Search Results
[CVPR2022] Multiview Transformers for Video Recognition
Transformer for Vision | Multimodal Transformers for Video | Session 7 | CVPR 2022
Multi-view Vision Transformers for Object Detection (MVViT) - Isaac-Medina et al., ICPR, 2022.
End to End Multi Person Pose Estimation With Transformers | CVPR 2022
DirecFormer: A Directed Attention in Transformer Approach to Robust Action Recognition
Self Supervised Video Transformer | CVPR 2022
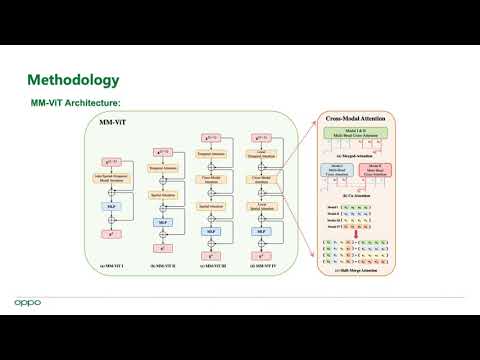
MM-ViT: Multi-Modal Video Transformer for Compressed Video Action Recognition
FVGC9: Combined CNN Transformer Encoder for Enhanced Fine-grained Human Action Recognition
Epipolar Transformer for Multi-view Pose Estimation (CV4ARVR 2020)
[CVPR 2022] TubeFormer-Deeplab: Video Mask Transformer
Keypoint Transformer: Solving Joint Identification in Challenging Hands and Object | CVPR 2022
CVPR 2022 Mask Transfiner for High-Quality Instance Segmentation

![[CVPR2022] Multiview Transformers for Video Recognition](https://img.youtube.com/vi/Tbb99IEbxik/hqdefault.jpg)






![[CVPR 2022] TubeFormer-Deeplab: Video Mask Transformer](https://img.youtube.com/vi/twoJyHpkTbQ/hqdefault.jpg)

